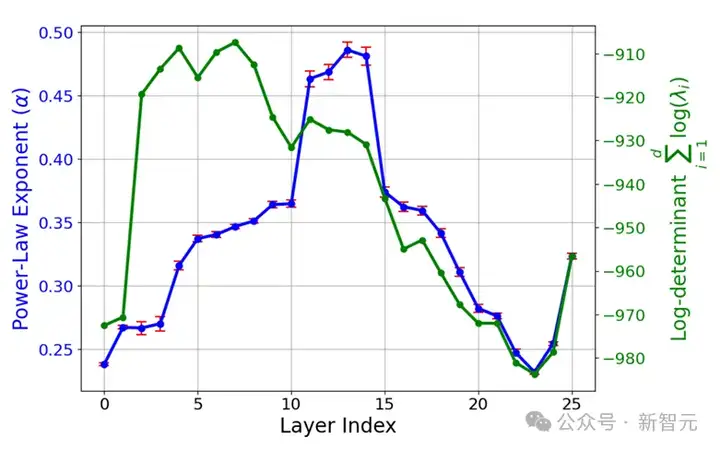
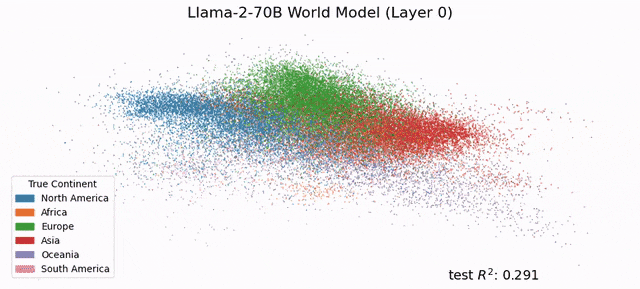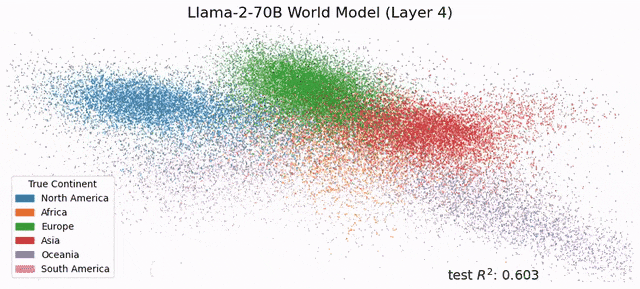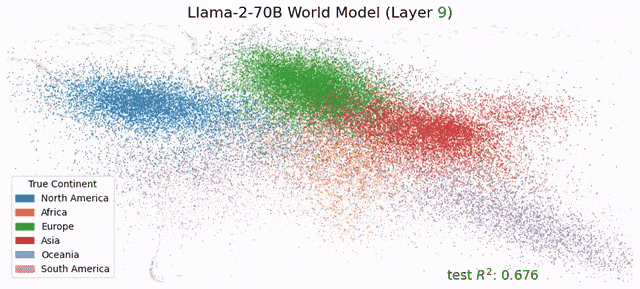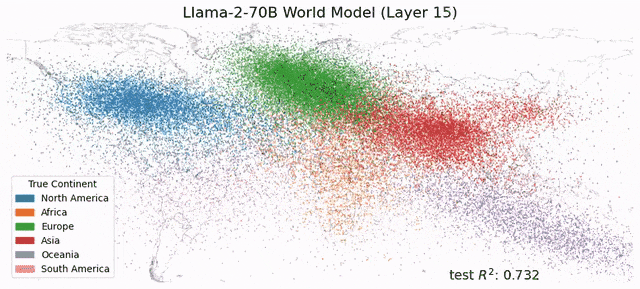
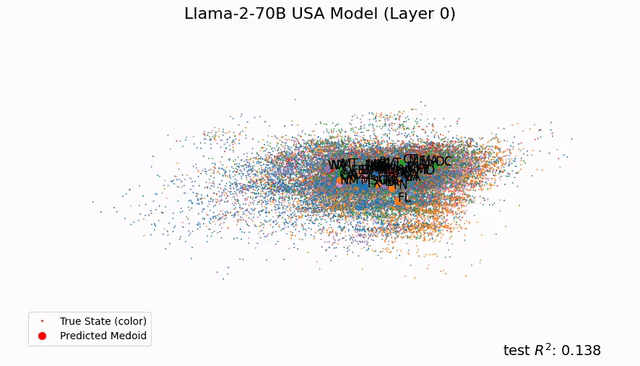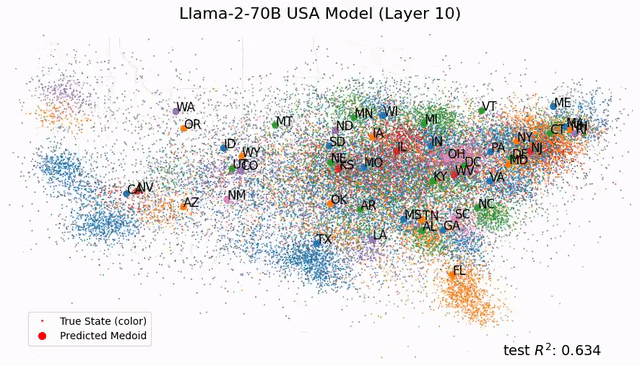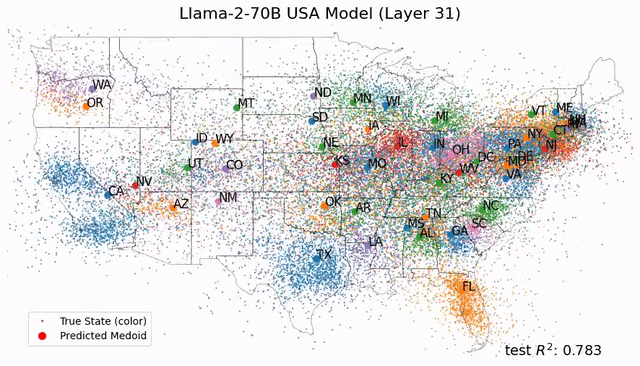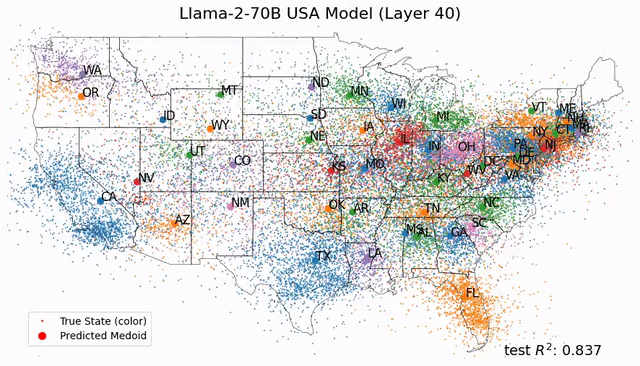
想象一下,你面前这盘蔬菜并非来自田间地头双手沾满泥土的农民,而是在金属与塑料构筑的垂直农业高塔中生长出来的科技结晶,你会是什么反应?
2018年在柏林时,我被当地超市里两三米高、5至6层不等的垂直农业生长柜深深吸引:它们形似超市的冷鲜柜,但坚硬光滑的玻璃壁橱内却没有任何花哨的食物包装,而是冒着幽幽的紫光。
大大小小的香草从每一层的塑料面板之间冒出头来,在冷柜内部的气流循环中身型笔挺地簌簌发抖。偶有像是工作人员的年轻人爬上梯架,把冷柜里成熟的植物摘择出来,整理放置在货架上。
本着朴素的好奇心,我开始了在一家垂直农业公司的实习。
一、“可控”的农业

刚刚入职的那一年,我像海绵一样吸收着新鲜的讯息和知识,在生产车间、工房、实验室和自己的工位之间打转,渐渐地了解了什么是垂直农业,以及工业设计师在这个系统中的职责。
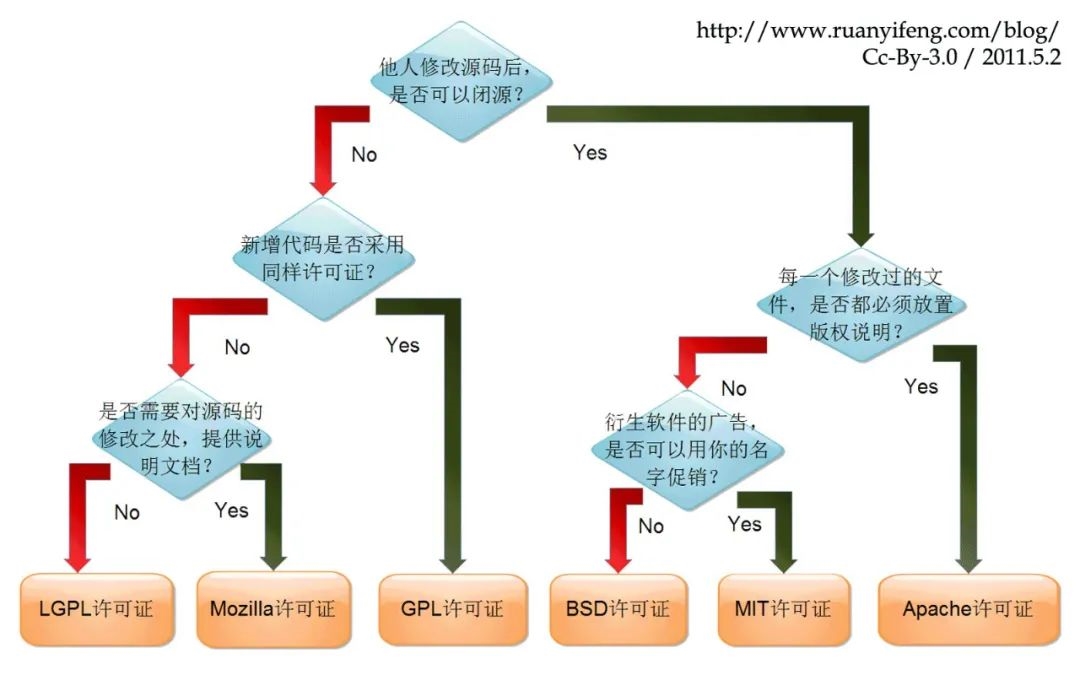
垂直农业一般使用无土栽培,常见有水培(Hydroponics)和气培(Aeroponics)两种方式,将肥料、氧气以及其他植物生长需要的元素按照配方注入水中,借助水泵发力,把营养液纵向输送到垂直结构的各个层面。
垂直农业设施则有半封闭和全封闭之分,前者依然会把太阳光照引入其植被的生长环境;后者则是在完全封闭的非自然空间,植物仅仅通过人造光进行光合作用,以实现对植物生长环境种种参数的精准调配。
我所在的公司主营水培全封闭多层结构式的生长柜,也是对技术要求最高、调控最精确的一类。

在传统的露地种植中,农民依靠经验和感知与大自然协作来培育作物。而在全封闭的水培生长柜中,植物生长环境的参数是完全量化的,各部门仅仅通过数字来交流彼此的需求:植物科学家给出他们需要的具体参数,工程师和设计师以此为基准,设计并满足这些参数的照明设备、灌溉系统、通风系统等硬件环境。
举个例子,垂直农业生长柜里的作物必须嵌在基底(substrate)中,基底无法自行漂浮在水面上,因此需要我们为其设计托盘和大小合适的凹孔。

凹孔在对植物根须起到包裹保护作用的同时,又要留有容纳根须生长的余裕。它既不能太过狭窄,以便保证根须旺盛的植物在收割时能轻松地连根拔起;也不能过于宽松,否则光线的渗透会引起绿藻泛滥、与植物争夺营养。
为了追求完美的的几何型态,我每天蹲守在工房3D打印机前打印模型、测试基底契合度、修改模型、再重新打印模型……如此循环往复,在打火机大小的尺度里调整着每个切面的尺寸,在0.1毫米与0.11毫米之间徘徊。
我不禁感慨:自然环境中生长的作物,恐怕不需要这么精细的“伺候”吧?
二、垂直农业:省事还是费事?
垂直农业不占用土地就能生产食物的“奇迹”叙事,实际上建立在一系列复杂且麻烦的流程之上。
垂直农业公司不光为零售商提供种植技术、硬件,还提供操作机器的人工。因此,提高机器的易用性、降低操作时的人工时长,就成了降低成本的关键。
为了把各环节的时间和人力成本压缩到最低,一些看似简单的维护超市水培柜的末端流程,如收割叶菜、包装、维护清理货架、记录收成健康状态、清洁生长柜、移栽幼苗等,也必须依靠垂直农业公司提供的手册指南。

这一指南的撰写和完善则来自设计师们对“农夫”(操作和维护水培柜的工作人员,行业简称farmer)无数次上机操作的跟踪。
我们对farmer的记录会用于分析每个步骤精确到分钟所花费的时间。基于这些观察与分析,再优化生长柜里硬件的排列和设计、增加操作流程中所需要的辅助工具、调整不同操作流程之间的步骤顺序,提升每一个人机交互的界面的易用性,尽可能地把生长柜所需的人工维护时间缩减到最低。
是不是像极了大卫·格雷伯在《毫无意义的工作》中描述的跟踪工人考评绩效的白领人员?

只不过我们手里拿的不是本本和表格,而是GoPro,影子一般地跟踪操作生长柜的工作人员,不加任何干涉地记录他们工作中的每个步骤、每个动作和每个失误。
三、为什么垂直农业不能解决全球粮食危机?
行业内常常听到这种说辞:在全球人口增长、气候变化进程加速的背景下,适宜农耕的土地资源逐渐减少,更大范围的粮食危机已依稀可见。因此,制造一个内部环境完全可控的的垂直农业也许会成为保障粮食安全的优先选项。
然而,每当垂直农业作为解决未来粮食危机的潜在选项被提出时,都不得不面对这个令人尴尬的问题,即适用于垂直农业系统的作物种类其实非常有限。
首先,规模化生产的机器很难照顾到不同作物植株的需求。
垂直农业的生长柜的层高往往取常种植作物的中间值,高于或者矮于这个的生长区间的作物都会被排除在外。在大型生长柜中,也很难针对某些单元区域的生长参数进行定点调控,一些品种特殊的小批量订单会成为烫手山芋。

除了种植和收割,收成的后期处理(post production)也是人力成本较高的一个步骤。不同的农产品的处理和分拣包装方式不同,减少作物的品种往往成为简化人工流程最简单直接的方式。
最重要的是,商用垂直农业公司目前还只能通过沙拉菜、香草,或是水分含量较高的西红柿、黄瓜、辣椒等农产品获利,因为这些作物耗能小,空间需求小,生长周期短,技术挑战较低,市场价值也较高;而无法通过种植含高蛋白、碳水化合物或者脂肪的粮食作物获益。
去年,德国垂直农业初创公司infarm倒是在埃及的COP27峰会上公布了在他们的垂直农业设施中成功种植小麦的实验结果。

该公司创始人在一份公开声明中表示:“第一轮试验结果表现杰出,预计每平方米年产量将达到11.7公斤(相当于亩产7800公斤)。若扩大规模,则相当于每公顷年产117吨,是露天种植产量的26倍。”
infarm并没有公开他们在实验中的耗能数据。但是根据公共艺术项目http://DISNOVATION.ORG的测算,在封闭环境中种植1平方米小麦,所需的能耗和外部营养物质等“真实成本估算”高达每公斤小麦200欧元(约1547元人民币),相当于当时欧洲小麦市价的一千多倍。


采用如此高成本高能耗的方式来保障粮食安全,显然既不经济,也不理性。
四、耗能与占地,垂直农业的真正成本
在垂直农业的营销话语中,“可持续”则是另一个引人瞩目的标签。
垂直农业宣称安装水培生产柜可以减少食物里程,有助于推广本地食物。遗憾的是,这些被锁在玻璃柜里的香菜、薄荷、鼠尾草,虽然勉强称得上来自本地,却完全和本地的自然、气候、生产者和食物网络脱节。

垂直农业还宣称可以节约水资源,却对系统高耗能的本质视而不见:垂直农业现阶段无法突破的瓶颈,在于必须消耗大量能源来供给系统里的LED人造光。
2021年的一份行业调研显示,336家可控环境农业公司(Controlled-enviroment Agriculture)中有64%未使用任何绿色或者再生能源。
使用化石燃料不仅不环保,且发电过程中能量转化的各个步骤中都存在能量损失,使得室内照明相对于阳光而言能源利用率极低。以耗能较低的绿叶蔬菜为例,普通温室仅为每千克5.4kWh,垂直农业每千克生产耗能则高达38.8kWh。
我还常听同行说,垂直农业的终极目标是将农业整合进更狭窄的占地面积,把原本被农业占用的大面积土地归还给大自然。因为土地农业不管被如何改进,提供的生物多样性也完全不能与大自然相媲美。


●北京天福园农场的生物多样性农业
但是考虑到垂直农业高耗能的本质,计算其真实的占地面积和资源消耗就不能只考虑工厂本身,而也要把为其供能的基建设施考虑在内。因此,看似环保、使用可再生能源的垂直农业公司,实质上也变相占据着为其供电的太阳能、风能设施的广大土地。
目前看来,除了生菜等低耗能的绿叶菜,通过垂直农业生产其他作物所“节省”的土地面积,并不足以抵消为其供电所占据的土地面积。
此外,已有的数据往往局限于垂直农业生产过程本身的能耗,而并不包括金属架构、人造光和传感器等基础设施生产所需能耗。这些基础设施在使用中还会经历磨损,一过使用年限就会成为工业或者电子垃圾。
如此种种,显然也与垂直农业想打造的环保叙事相悖。
五、后 感
俄乌战争期间,垂直农业的局限在能源危机的连锁反应中暴露殆尽,整个行业遭受了沉重打击。
美国机器人垂直农业公司Fifth Season于去年11月关停;几乎同一时间,德国的infarm公司宣告裁员一半以上员工;法国公司集装箱农业公司Agricool于今年1月宣告破产;行业领头羊AeroFarms则于今年6月申请破产保护……这个技术中心主义的“奇迹”无疑已经跌落神坛。
在全球人口增长、气候变化进程加速的大背景下,也许制造一个内部环境完全可控的的垂直农业确实会成为应对粮食危机的可选项之一。但是资本逐利的当下,众多初创科技公司为了满足投资人的期待,只能陷入大规模扩张乃至入不敷出的死循环。
然而,垂直农业也可以作为一种更开源、更平民、更去中心化、可以被普通人居家实践的方法,以水培蔬菜的形式发扬光大。它可以作为园艺爱好,出现在自家阳台、厨房和屋顶;也可以重建人与人之间的联系、发挥教育意义,出现在社区的公共空间。
在这种状态下,垂直农业不再披着神秘的技术外衣,而成了一种生活场景:它拉近了人与食物的距离,在都市有限的土地资源里,为想要创造绿色用地的人添加一个新的选项。
也许正是这种“低技术(low-tech)“的垂直农业实践,才更能启发我们体会土地的珍贵和生产者的不易,重拾对大自然的敬畏之心,辨明环保与可持续的真义。